


In the previous article, we discussed the TVS Motor way of data science for identyfing business problems that can be solved using AI/ML. We also explained how a lead classification model can be used to drive follow-up prioritisation and personalisation of marketing communications. In this article, we will talk about exploratory data analysis, feature engineering & model development and selection process.
Exploratory data analysis and feature engineering
We used open-source automated tools such as pandas-profiling , data-prep and sweetviz to study the data quality and data distribution for all features. At this stage, we were looking for any gaps in the available data to come up with right imputation strategy and bi-variate analysis to understand the linkage between underlying features and the event rate. Since each tool has its own advantages and limitations, we used all of them depending on our requirement. The relative capabilities of these tools are shown in the chart below.
|
Considerations |
Pandas Profiling |
Sweetbiz |
DataPrep |
|
Number of data frames that can be visualised together |
One |
Two |
Multiple |
|
Backend graphing library |
Matplotlib |
Matplotlib |
Bokeh |
|
Auto EDA report generation |
Slow |
Fast |
Fast |
|
Univariate analysis |
Yes |
Yes |
Yes |
|
Bi-variate analysis |
No |
Yes |
Yes |
|
Open source |
Yes |
Yes |
Yes |
Some of the tasks we performed to get the final dataframe for model training are:
- Imputation strategy for missing data
- Handled missing data for categorical features
- For numerical features imputed missing values with the median
- Filled in missing data using predictive models
- Unbalanced sample – As the target variable was highly imbalanced we employed up-sampling, down-sampling and class weights techniques.
- Outlier treatment – From the model training experiments we observed that tree-based models are able to generalise the target much better than any other types of models. Since all the tree-based algorithms are robust enough to handle outliers by default there was no need for us perform outlier treatment explicitly.
- Variable transformation – Applied cyclic transformation to all the datetime features.
- Derived Features – Derived features such as lead’s proximity from dealership location, purchase propensity at hyperlocal geographies and other seasonal features such as season.
- Feature Encoding – Applied various types of categorical encoding techniques like Target Encoding, Catboost Encoding and Weight Evidence for categorical features based on the cardinality.
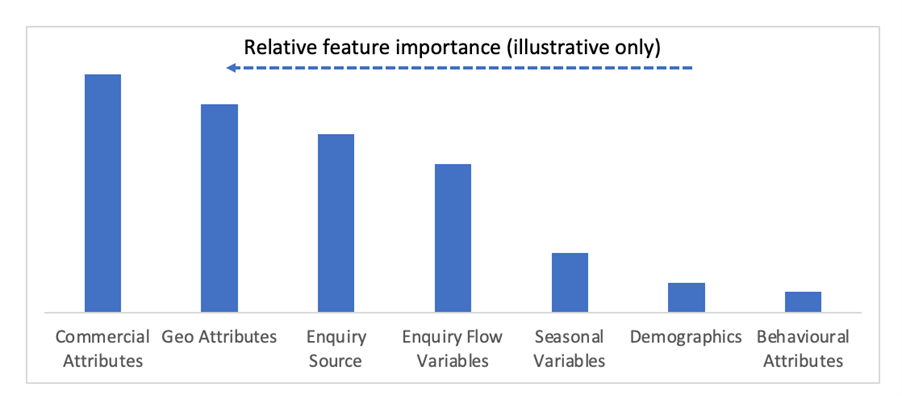
We used ELI5 framework to understand the relative importance of variables, including derived features, to ensure better model explainability. Some of the important features of the training dataset are listed below in the order of importance.
Model Development and Evaluation
We built a linear model as a baseline and expanded to kernal based models and ensembles. We observed that gradient boosting algorithms such as XGBoost, CatBoost LightGBM were generalising target better than others, specifically XGBoost being the best with a good f2 score.
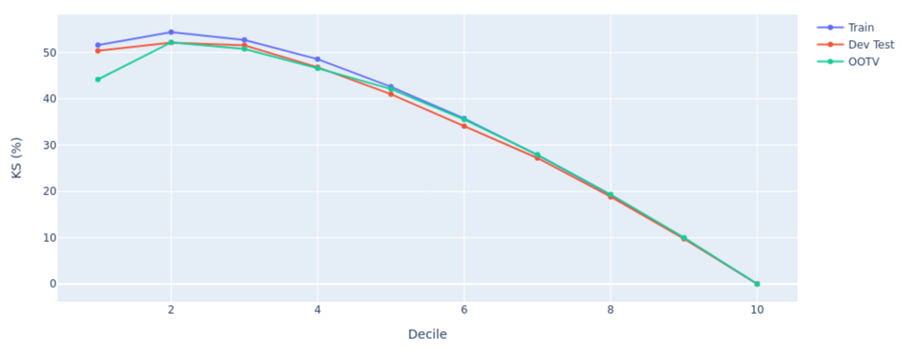
We used the F2 score as an evaluation metric to assess the performance of the models because it balances recall and precision with more weightage to recall. Additionally, we used KS statistic to understand the rank ordering capability of the model.
We had divided the our data into train, test and out of time (OOT) datasets. We compared KS scores across these data sets to assess the model stability (as shown in the chart below) to finalize a production ready model.
Additionally, to ease and automate the model training, hyper-parameter tuning and selection, we used the fast library for AutoML (FLAML) with sklearn pipelines to parallelly train and automatically find best performing machine learning models.
Stay tuned to know about our deployment strategy and different pipelines we set up to monitor performance of the above solution.
Comments (18)
ZAP
23 Jun 2022
9886643450
02 Apr 2023
9886643450
02 Apr 2023
9886643450
02 Apr 2023
katana
26 Apr 2023
katana
02 May 2023
katana
02 May 2023
katana
24 May 2023
katana
14 Jun 2023
NadineLem
22 Oct 2024
CBD exceeded my expectations in every way thanks CBD https://www.cornbreadhemp.com/pages/how-long-is-thc-gummies-shelf-life . I've struggled with insomnia for years, and after infuriating CBD because of the first age, I finally trained a full eventide of calm sleep. It was like a bias had been lif
Jamesalill
25 Oct 2024
Disquieting [url=https://www.nothingbuthemp.net/pages/how-much-delta-9-tincture-should-i-take ]How much Delta 9 tincture should I take?[/url] has been quite the journey. As someone rapier-like on usual remedies, delving into the coterie of hemp has been eye-opening. From THC tinctures to hemp seeds
MatthewAquar
25 Oct 2024
Fatiguing https://www.nothingbuthemp.net/pages/how-do-thc-mood-gummies-help-improve-emotional-well-being has been perfectly the journey. As someone pointed on usual remedies, delving into the world of hemp has been eye-opening. From THC tinctures to hemp seeds and protein competency, I've explored
thc drinks
29 Oct 2024
Disquieting thc drinks has been somewhat the journey. As someone rapier-like on unpretentious remedies, delving into the to the max of hemp has been eye-opening. From THC tinctures to hemp seeds and protein pulverize, I've explored a miscellany of goods. Despite the disorder neighbourhood hemp, rese
Joannnam
30 Oct 2024
I've been in reality impressed with CBD gummies and like [url=https://www.cornbreadhemp.com/pages/can-thc-gummies-be-consumed-while-operating-heavy-machinery ]Can THC Gummies be consumed while operating heavy machinery?[/url]. They're not at worst delicious but also incredibly nearby in return gett
mzaenolufj
01 Nov 2024
Muchas gracias. ?Como puedo iniciar sesion?
chris L
17 Dec 2025
The website[CoscoAI](https://coscoai.com/zimage) can generate 100 photos from one prompt (with multiple variables inserted in the prompt). I haven't seen this anywhere else yet.
CryptoRobotics
22 May 2026
This platform enables businesses to monetize crypto signals through subscriptions and performance models: <a href="https://cryptorobotics.ai/learn/white-label-signal-bots-by-cryptorobotics/">https://cryptorobotics.ai/learn/white-label-signal-bots-by-cryptorobotics/</a>
Germany World Cup Flops
15 Jun 2026
O Buffalo Win tá pagando muito na virada do dia! Já fiz o PIX de R$ 500.